

免费源代码下载整理 - 云代码空间
—— 每天更新整理各种PHP、JSP、ASP源代码,敬请关注我的微博 http://weibo.com/freecodedownload
总体来说,优化的原则和对单独的表做优化是一样的,保证对磁盘上表的扫描次数减小。
我们的表结构如下:
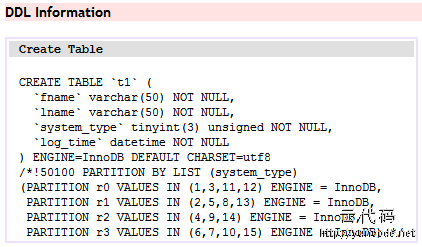
这里已经插入2W多行数据进行测试。
看看这条查询。
SELECT * FROM t1 WHERE system_type IN (1,2)
UNION ALL
SELECT * FROM t1 WHERE system_type = 3;
这条语句对system_type字段过滤了两次,然后进行了一次UNION ALL。 但是不知道,其实对两个分区一共进行了三次全表扫描。
我们改成这样:
SELECT * FROM t1 WHERE system_type IN (1,3)
UNION ALL
SELECT * FROM t1 WHERE system_type = 2;
看似简简单单的改变,我们把对两个分区的扫描从三次减少到了两次。 但是这样,开销也很大,能不能把UNION ALL去掉呢?当然可以。
SELECT * FROM t1 WHERE system_type >0 and system_type < 4;
去掉了UNION ALL,但是遇到的问题是对分区的扫描变成了范围查找,而且上下限不固定,相对来说,还有优化的空间。
我们改下对system_type列的过滤条件,变成如下:
SELECT * FROM t1 WHERE system_type in(1,2,3);
idselect_typetablepartitionstypepossible_keyskeykey_lenrefrowsExtra
1SIMPLEt1r0,r1ALL\N\N\N\N17719Using where
现在,依然是范围扫描,但是上下限就很明了了。这样对扫描分区来说,很快的找到上下限,比之前来的要快,开销来的要小点了。
但是貌似还可以优化, 虽然过滤条件的上下限明显了,但是对于区域之内的扫描还是全分区(相当于整个表的全表。)。
OK,那现在给这个列加上索引吧。
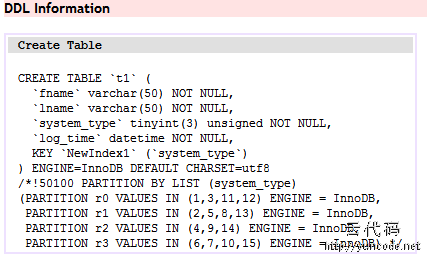
ALTER TABLE t1 ANALYZE PARTITION r0,r1;
SELECT * FROM t1 WHERE system_type in(1,2,3);
idselect_typetablepartitionstypepossible_keyskeykey_lenrefrowsExtra
1SIMPLEt1r0,r1rangeNewIndex1NewIndex11\N6462Using where
当然,我们的例子非常简单, 这里只是为了演示下在水平分区下如何进行SQL优化。