

java - 云代码空间
—— 员工第一,客户第二。没有他们,就没有阿里巴巴。也只有他们开心了,我们的客户才会开心。而客户们那些鼓励的言语,鼓励的话,又会让他们像发疯一样去工作,这也使得我们的
Zend Memory Manager, 以下简称Zend MM, 是PHP中内存管理的逻辑. 其中有一个关键数据结构: zend_mm_heap:
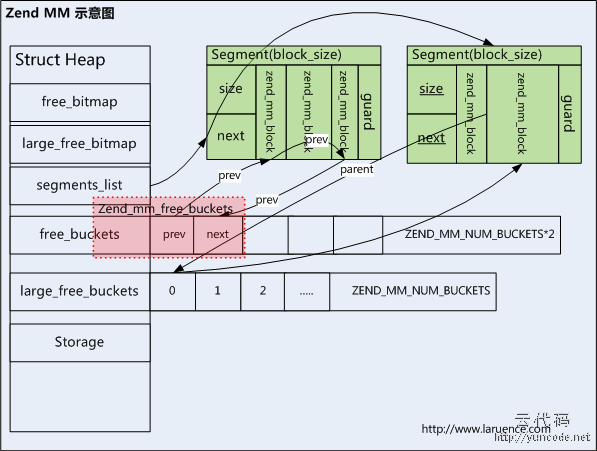
Zend MM把内存非为小块内存和大块内存俩种, 区别对待, 对于小块内存, 这部分是最最常用的, 所以追求高性能. 而对于大块内存, 则追求的是稳妥, 尽量避免内存浪费.
所以, 对于小块内存, PHP还引入了cache机制:
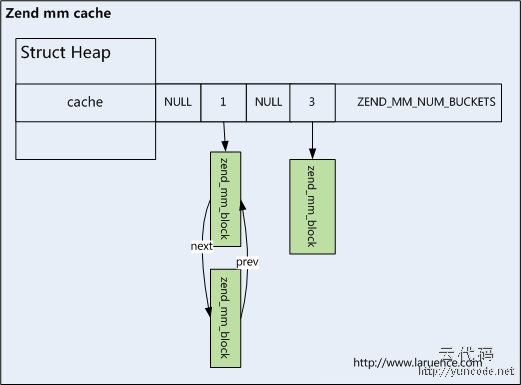
Zend MM 希望通过cache尽量做到, 一次定位就能查找分配.
而一个不容易看懂的点是free_buckets的申明:
Q: 为什么free_buckets数组的长度是ZEND_MM_NUMBER_BUCKET个?
A: 这是因为, PHP在这处使用了一个技巧, 用一个定长的数组来存储ZEND_MM_NUMBER_BUCKET个zend_mm_free_block, 如上图中红色框所示. 对于一个没有被使用的free_buckets的元素, 唯一有用的数据结构就是next_free_block和prev_free_block, 所以, 为了节省内存, PHP并没有分配ZEND_MM_NUMBER_BUCKET * sizeof(zend_mm_free_block)大小的内存, 而只是用了ZEND_MM_NUMBER_BUCKET * (sizeof(*next_free_block) + sizeof(*prev_free_block))大小的内存..
我们来看ZEND_MM_SMALL_FREE_BUCKET宏的定义:
之后, Zend MM 保证只会使用prev和next俩个指针, 所以不会造成内存读错..
那么, 第二个不容易看懂的点, 就是PHP对large_free_buckets的管理, 先介绍分配(TIPI项目组对此部分的描述有些含糊不清):
large_free_buckets可以说是一个建树和双向列表的结合:
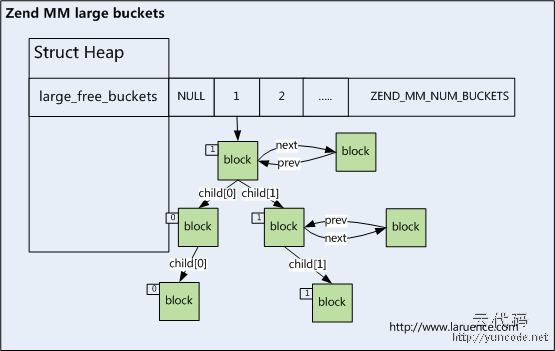
large_free_buckets使用一个宏来决定某个大小的内存, 落在什么index上:
zend_mm_high_bit获取true_size中最高位1的序号(zend_mm_high_bit), 对应的汇编指令是bsr(此处, TIPI项目错误的说明为: “这个hash函数用来计算size的位数,返回值为size二进码中1的个数-1″).
也就是说, 每一个在large_free_buckets中的元素, 都保持着指向一个大小为在对应index处为1的size的内存块的指针. 诶, 有点绕口, 举个例子:
比如对于large_free_buckets[2], 就只会保存, 大小在0b1000到0b1111大小的内存. 再比如: large_free_buckets[6], 就保存着大小为0b10000000到0b11111111大小的内存的指针.
这样, 再分配内存的时候, Zend MM就可以快速定位到最可能适合的区域来查找. 提高性能.
而, 每一个元素又同时是一个双向列表, 保持着同样size的内存块, 而左右孩子(child[0]和child[1])分别代表着键值0和1, 这个键值是指什么呢?
我们来举个例子, 比如我向PHP申请一个true_size为0b11010大小的内存, 经过一番步骤以后, 没有找到合适的内存, PHP进入了zend_mm_search_large_block的逻辑来在large_free_buckets中寻找合适的内存:
1. 首先, 计算true_size对应的index, 计算方法如之前描述的ZEND_MM_LARGE_BUCKET_INDEX
2. 然后在一个位图结构中, 判断是否存在一个大于true_size的可用内存已经存在于large_free_buckets, 如果不存在就返回:
3. 判断, free_buckets[index]是否存在可用的内存:
4. 如果存在, 则从free_buckets[index]开始, 寻找最合适的内存, 步骤如下:
4.1. 从free_buckets[index]开始, 如果free_buckets[index]当前的内存大小和true_size相等, 则寻找结束, 成功返回.
4.2. 查看true_size对应index后(true_size << (ZEND_MM_NUM_BUCKETS - index))的当前最高位, 如果为1. 则在free_buckets[index]->child[1]下面继续寻找, 如果free_buckets[index]->child[1]不存在, 则跳出. 如果true_size的当前最高位为0, 则在free_buckets[index]->child[0]下面继续寻找, 如果free_buckets[index]->child[0]不存在, 则在free_buckets[index]->child[1]下面寻找最小内存(因为此时可以保证, 在free_buckets[index]->child[1]下面的内存都是大于true_size的)
4.3. 出发点变更为2中所述的child, 左移一位ture_size.
5. 如果上述逻辑并没有找到合适的内存, 则寻找最小的”大块内存”:
注意上面的逻辑, (p = p->child[p->child[0] != NULL]), PHP在尽量寻找最小的内存.
为什么说, large_free_buckets是个键树呢, 从上面的逻辑我们可以看出, PHP把一个size, 按照二进制的0,1做键, 把内存大小信息反应到了键树上, 方便了快速查找.
另外, 还有一个rest_buckets, 这个结构是个双向列表, 用来保存一些PHP分配后剩下的内存, 避免无意义的把剩余内存插入free_buckets带来的性能问题(此处, TIPI项目错误的描述为: “这是一个只有两个元素的数组。 而我们常用的插入和查找操作是针对第一个元素,即heap->rest_buckets[0]“).