

Python自学 - 云代码空间
—— python自学——怎么学习python,自学python要多久?python+人工智能+人工智能+人工智能+大数据分析
随着短视频的大火,不仅可以给人们带来娱乐,还有热点新闻时事以及各种知识,刷短视频也逐渐成为了日常生活的一部分。本文以一个简单的小例子,简述如何通过Pyhton依托Selenium来爬取短视频,仅供学习分享使用,如有不足之处,还请指正。
在爬取视频之前,需要分析目标结构,本视频爬取分析可分为三步,具体如下所示:
热榜目录是一个ul标签,每一个热榜对象一个li子标签,分别包含热度,标题等内容。点击标题链接可以进入具体视频播放页面,目标分析如下所示:
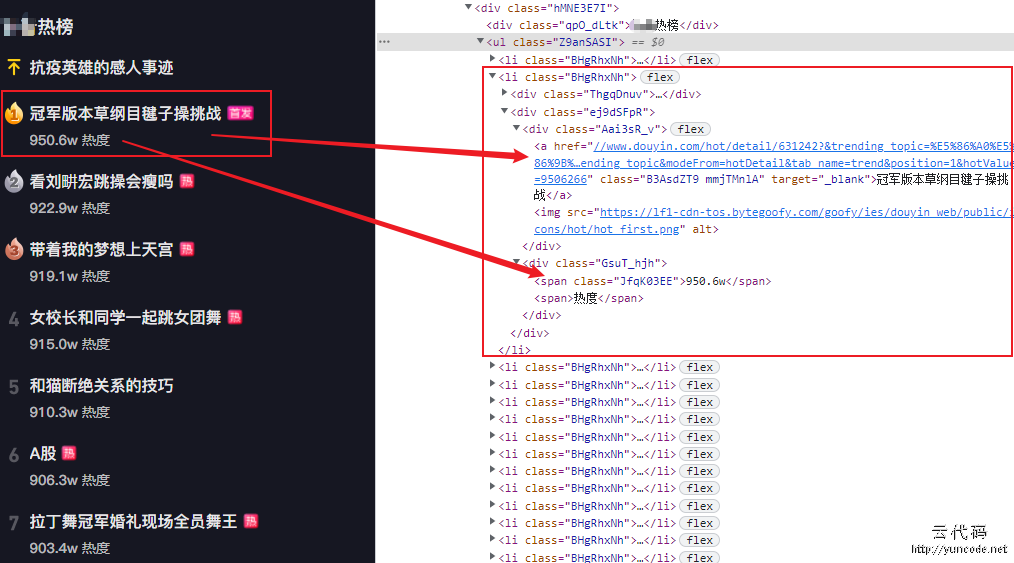
视频在video标签中播放,短视频播放的真实地址,在video的source子标签中,且为了保证播放质量,video下有三个source,任取其一即可,如下所示:

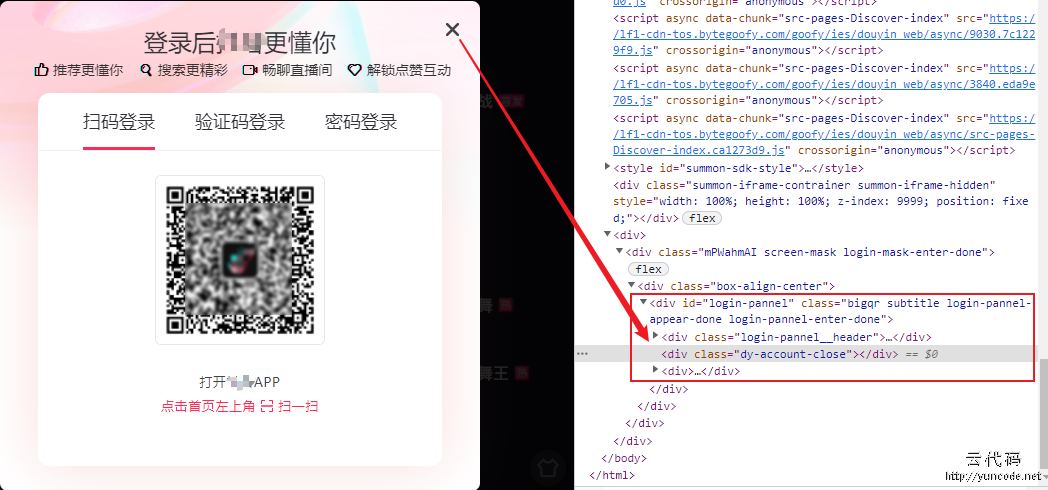
在爬取过程中,经过弹出需要登录的窗口,需要及时关闭掉,否则可能会导致找不到页面元素,从而爬取不成功。如下所示:
经过以上分析,就可以编写爬虫代码了,如下所示:
通过获取页面上对应的信息,解析出热点视频的目录,如下所示:
self.__driver.get(self.__url)
self.close_popup_window()
# 4. 最大化窗口
self.__driver.maximize_window()
time.sleep(self.__wait_sec)
# 打开以后,根据class=BHgRhxNh获取ul下的li
if self.checkIsExistsByClass(cls='BHgRhxNh'):
# 获取
hots = self.__driver.find_elements(by=By.CLASS_NAME, value='BHgRhxNh')
hot_infos = []
index = 0
for hot in hots:
hot_info = {}
a = hot.find_element(by=By.TAG_NAME, value='a')
href = a.get_attribute("href")
text = a.text
hot_info['url'] = href
hot_info['text'] = text
if index > 0:
div = hot.find_element(by=By.CLASS_NAME, value='GsuT_hjh')
if div is not None:
hot_value = div.find_element(by=By.TAG_NAME, value='span').text
hot_info['value'] = hot_value
hot_infos.append(hot_info)
index = index + 1
print(hot_infos)
打开单个热点视频的url,并解析真实短视频播放url,如下所示:
def open_video_html(self, url):
"""打开具体视频的页面"""
self.__driver.get(url=url)
time.sleep(1)
self.close_popup_window() # 关闭弹窗
video = self.__driver.find_element(by=By.TAG_NAME, value='video')
source = video.find_element(by=By.TAG_NAME, value='source')
src = source.get_attribute('src')
return src
获取真实的url后,即可进行下载,如下所示:
def download_video(self, url, video_name):
"""根据视频源地址进行下载"""
if os.path.exists(video_name):
# 如果已重新下载过,则不需要再次下载
return
else:
with open(video_name, 'wb') as fp:
fp.write(requests.get(url).content)
在爬取过程中,经常弹出需要登录的遮罩窗口,需要进行关闭,如下所示:
def close_popup_window(self):
try:
login = self.__driver.find_element(by=By.ID, value='login-pannel')
if login is not None:
login.find_element(by=By.CLASS_NAME, value='dy-account-close').click()
except BaseException as e:
pass
try:
login = self.__driver.find_element(by=By.CLASS_NAME, value='GaDkStRD')
if login is not None:
btns = login.find_elements(by=By.TAG_NAME, value='button')
for btn in btns:
if btn.text == '取消':
btn.click()
break
except BaseException as e:
pass
在爬取成功后,对爬取的短视频的相关内容进行保存,如下所示:
def save_data(self, hot_infos):
"""
保存数据
:param res_list: 保存的内容文件
:return:
"""
t = time.strftime("%Y-%m-%d", time.localtime())
with open(f'logs[{t}].json', 'a', encoding='utf-8') as f:
res_list_json = json.dumps(hot_infos, ensure_ascii=False)
f.write(res_list_json)
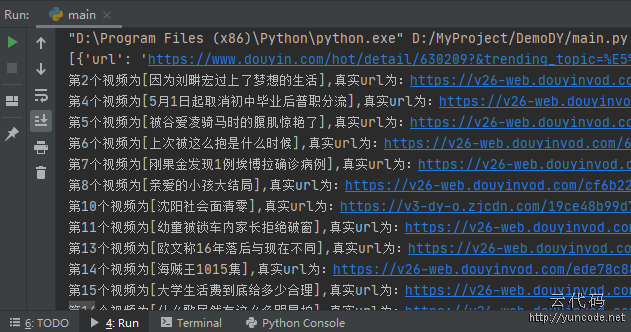
程序开发完成后,运行示例如下所示:
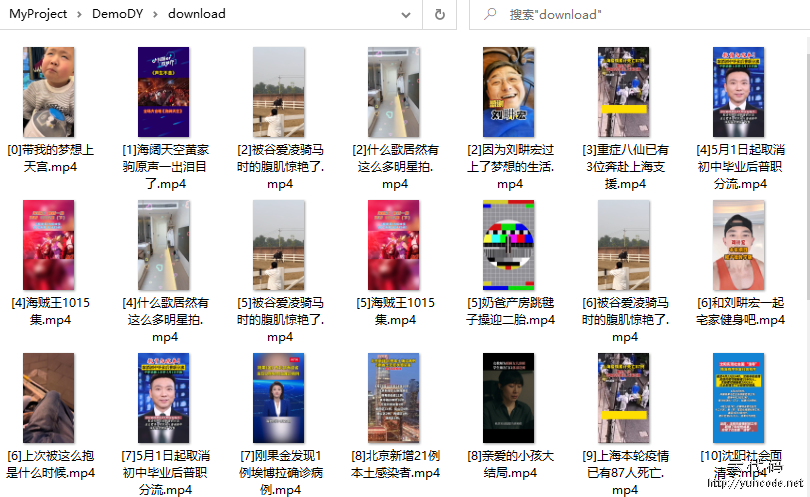
爬取的视频保存在download目录下,如下所示:
为什么会采用selenium进行本次短视频的爬取,而不直接采用requests库,原因如下:
由于以上两点原因,结合selenium的特点及优势,所以最终采用selenium进行此次爬虫的最佳选择。