

小蜜锋 - 云代码空间
—— 技术宅拯救世界!
随着业务的增长 simhash的数据也会暴增,如果一天100w,10天就1000w了。我们如果插入一条数据就要去比较1000w次的simhash,计算量还是蛮大,普通PC 比较1000w次海明距离需要 300ms ,和5000w数据比较需要1.8 s。看起来相似度计算不是很慢,还在秒级别。给大家算一笔账就知道了:
随着业务增长需要一个小时处理100w次,一个小时为3600 *1000 = 360w毫秒,计算一下一次相似度比较最多只能消耗 360w / 100w = 3.6毫秒。300ms慢吗,慢!1.8S慢吗,太慢了!很多情况大家想的就是升级、增加机器,但有些时候光是增加机器已经解决不了问题了,就算增加机器也不是短时间能够解决的,需要考虑分布式、客户预算、问题解决的容忍时间?头大时候要相信人类的智慧是无穷的,泡杯茶,听下轻音乐:)畅想下宇宙有多大,宇宙外面还有什么东西,程序员有什么问题能够难倒呢?
加上客户还提出的几个,汇总一下技术问题:
目前我们估算一下存储空间的大小,就以JAVA 来说,存储一个simhash 需要一个原生态 lang 类型是64位 = 8 byte,如果是 Object 对象还需要额外的 8 byte,所以我们尽量节约空间使用原生态的lang类型。假设增长到最大的5000w数据, 5000w * 8byte = 400000000byte = 400000000/( 1024 * 1024) = 382 Mb,所以按照这个大小普通PC服务器就可以支持,这样第三个问题就解决了。
比较5000w次怎么减少时间呢?其实这也是一个查找的过程,我们想想以前学过的查找算法: 顺序查找、二分查找、二叉排序树查找、索引查找、哈希查找。不过我们这个不是比较数字是否相同,而是比较海明距离,以前的算法并不怎么通用,不过解决问题的过程都是通用的。还是和以前一样,不使用数学公式,使用程序猿大家都理解的方式。还记得JAVA里有个HashMap吗?我们要查找一个key值时,通过传入一个key就可以很快的返回一个value,这个号称查找速度最快的数据结构是如何实现的呢?看下hashmap的内部结构:
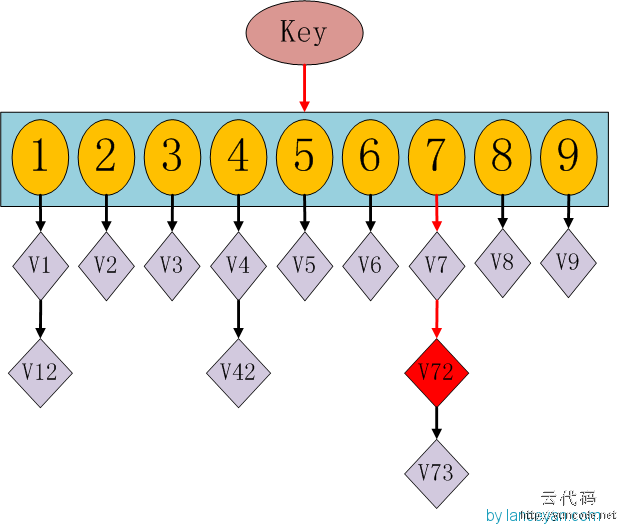
如果我们需要得到key对应的value,需要经过这些计算,传入key,计算key的hashcode,得到7的位置;发现7位置对应的value还有好几个,就通过链表查找,直到找到v72。其实通过这么分析,如果我们的hashcode设置的不够好,hashmap的效率也不见得高。借鉴这个算法,来设计我们的simhash查找。通过顺序查找肯定是不行的,能否像hashmap一样先通过键值对的方式减少顺序比较的次数。看下图:
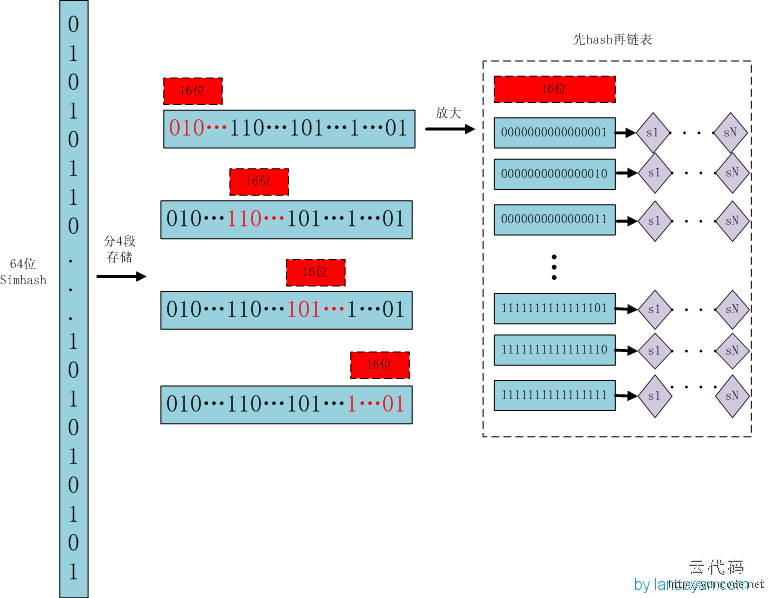
存储:
1、将一个64位的simhash code拆分成4个16位的二进制码。(图上红色的16位)
2、分别拿着4个16位二进制码查找当前对应位置上是否有元素。(放大后的16位)
3、对应位置没有元素,直接追加到链表上;对应位置有则直接追加到链表尾端。(图上的 S1 — SN)
查找:
1、将需要比较的simhash code拆分成4个16位的二进制码。
2、分别拿着4个16位二进制码每一个去查找simhash集合对应位置上是否有元素。
2、如果有元素,则把链表拿出来顺序查找比较,直到simhash小于一定大小的值,整个过程完成。
原理:
借鉴hashmap算法找出可以hash的key值,因为我们使用的simhash是局部敏感哈希,这个算法的特点是只要相似的字符串只有个别的位数是有差别变化。那这样我们可以推断两个相似的文本,至少有16位的simhash是一样的。具体选择16位、8位、4位,大家根据自己的数据测试选择,虽然比较的位数越小越精准,但是空间会变大。分为4个16位段的存储空间是单独simhash存储空间的4倍。之前算出5000w数据是 382 Mb,扩大4倍1.5G左右,还可以接受:)
通过这样计算,我们的simhash查找过程全部降到了1毫秒以下。就加了一个hash效果这么厉害?我们可以算一下,原来是5000w次顺序比较,现在是少了2的16次方比较,前面16位变成了hash查找。后面的顺序比较的个数是多少? 2^16 = 65536, 5000w/65536 = 763 次。。。。实际最后链表比较的数据也才 763次!所以效率大大提高!
到目前第一点降到3.6毫秒、支持5000w数据相似度比较做完了。还有第二点同一时刻发出的文本如果重复也只能保留一条和短文本相识度比较怎么解决。其实上面的问题解决了,这两个就不是什么问题了。