[python]代码库
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import os
import time
def getHTMLText(url,headers):
try:
r=requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "爬取失败"
def parsehtml(namelist,urllist,html):
url='http://www.tom61.com/'
soup=BeautifulSoup(html,'html.parser')
t=soup.find('dl',attrs={'class':'txt_box'})
i=t.find_all('a')
for link in i:
urllist.append(url+link.get('href'))
namelist.append(link.get('title'))
print(urllist)
print(namelist)
return urllist,namelist
def main():
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
}
urllist=[]#定义存放故事URL的列表
namelist=[]#定义存放故事名字的列表
if not os.path.exists('myshortStories'):#将所有的故事放到一个目录下
os.mkdir('myshortStories')
for i in range(1,20):#控制分页(每页有70个故事)
if i==1:#爬取故事的地址和故事名
url='http://www.tom61.com/ertongwenxue/shuiqiangushi/index.html'
else:
url='http://www.tom61.com/ertongwenxue/shuiqiangushi/index_'+str(i)+'.html'
print ("正在爬取第%s页的故事链接:" % (i))
print (url+'\n')
html=getHTMLText(url,headers)
urls,storiesNames = parsehtml(namelist,urllist,html)
littleStories = []
m=0
for url in urls:#通过URL在爬取具体的故事内容
print('已经爬取了'+str(((i-1)*70+m))+'篇文章')
littlestory = ''
storyhtml = getHTMLText(url,headers)
soup = BeautifulSoup(storyhtml, 'html.parser')
t = soup.find('div', class_='t_news_txt')
ptexts = t.find_all('p')
for ptext in ptexts: #将一个故事作为数列的一个元素
storytext = ptext.text
littlestory = littlestory+storytext
littleStories.append(littlestory.replace('\u3000\u3000',''))
m=m+1
time.sleep(1)
myLittleStorySets = dict(zip(storiesNames,littleStories))#将故事名和故事内容拼接成字典的形式
print("爬取链接完成")
k=0
for storyName, storyContent in myLittleStorySets.items():
textName = 'myshortStories/'+'Day'+str(((i-1)*70+k))+'.txt'#为每个故事建立一个TXT文件
with open(textName, 'a', encoding='utf-8') as f:
f.write(storyName)
f.write('\n')
f.write(storyContent)
k = k + 1
print("正在写入Day"+str(((i-1)*70+k))+"故事")
time.sleep(1)
if __name__=='__main__':
main()
[代码运行效果截图]




初级程序员
by: 老猫肥 发表于:2020-05-14 19:40:24 顶(2) | 踩(1) 回复
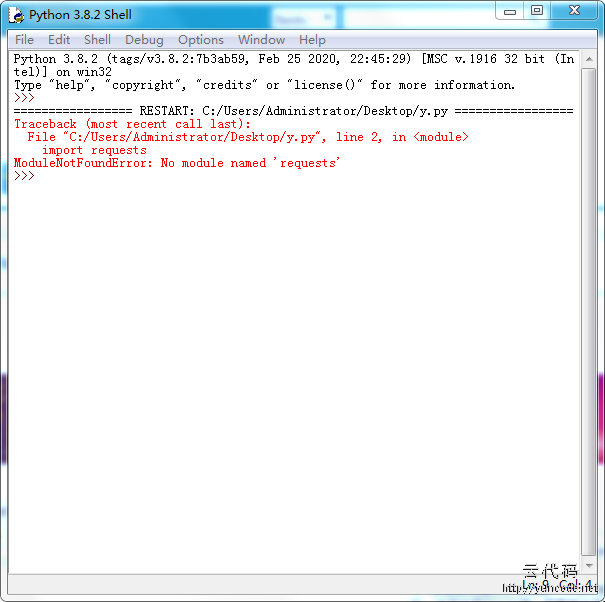
为什么我的出错了?
回复评论