[python]代码库
# encoding=utf-8
from utils import util, dbmysql
import re, time,datetime,requests
from lxml import etree
def rule(path,content):
res=re.findall(path, content)
if res!=[]:
response=res[0]
else:
response=''
return response
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36"}
def headers():
timestamp=int(time.time())
head_detail={
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36"
}
return head_detail
def ssjzw():
for page in range(1,100):
try:
res = util.get('https://www.ssjzw.com/jzzp/pn{}'.format(page))
content = res['data'].decode('gb2312','ignore').replace('\n', '').replace('\r', '').replace('\t', '')
url = re.findall('<li class="tys" style="float:left;width:360px;"><a href="(.*?)" target=', content)
i=0
for num in url:
i+=1
sql = "select * from ssjzw where url='%s'" % num
rs = dbmysql.fetchall(sql)
if len(rs) == 0:
try:
timestamp=int(time.time())
detail =util.get(num,headers=headers())
content_detail = detail['data'].decode('gb2312','ignore').replace('\n', '').replace('\r', '').replace('\t', '')
# 公司匹配
company_ture = re.findall('<ul>招聘单位:<a href=.*?target="_blank">(.*?)</a></ul>', content_detail)
if company_ture == []:
company_2= re.findall('<ul>招聘单位:(.*?)</ul>', content_detail)
if company_2 == []:
company=''
else:
company=company_2[0]
else:
company = company_ture[0]
area=rule('<ul>兼职地区:<a href=.*?>(.*?)兼职',content_detail)
phonenum=rule("innerHTML='(.*?)'",content_detail)
uploadTime=rule('<ul>更新时间:(.*?)</ul>',content_detail)
sql2 = "insert into ssjzw (url,company,area,phonenum,uploadTime,insertTime) value ('%s','%s','%s','%s','%s','%s')" % (num,company,area,phonenum,uploadTime,datetime.datetime.now())
rs=dbmysql.execute(sql2)
if rs==False:
print("上上兼职网第{}页第{}条insert失败".format(page,i))
print("正在insert上上兼职网第{}页第{}条{}".format(page,i,num))
time.sleep(2)
except Exception as e:
print(num)
print(e)
continue
else:
print("上上兼职网第{}页第{}条已存在".format(page,i))
time.sleep(2)
continue
except Exception as e:
print(e)
continue
ssjzw()
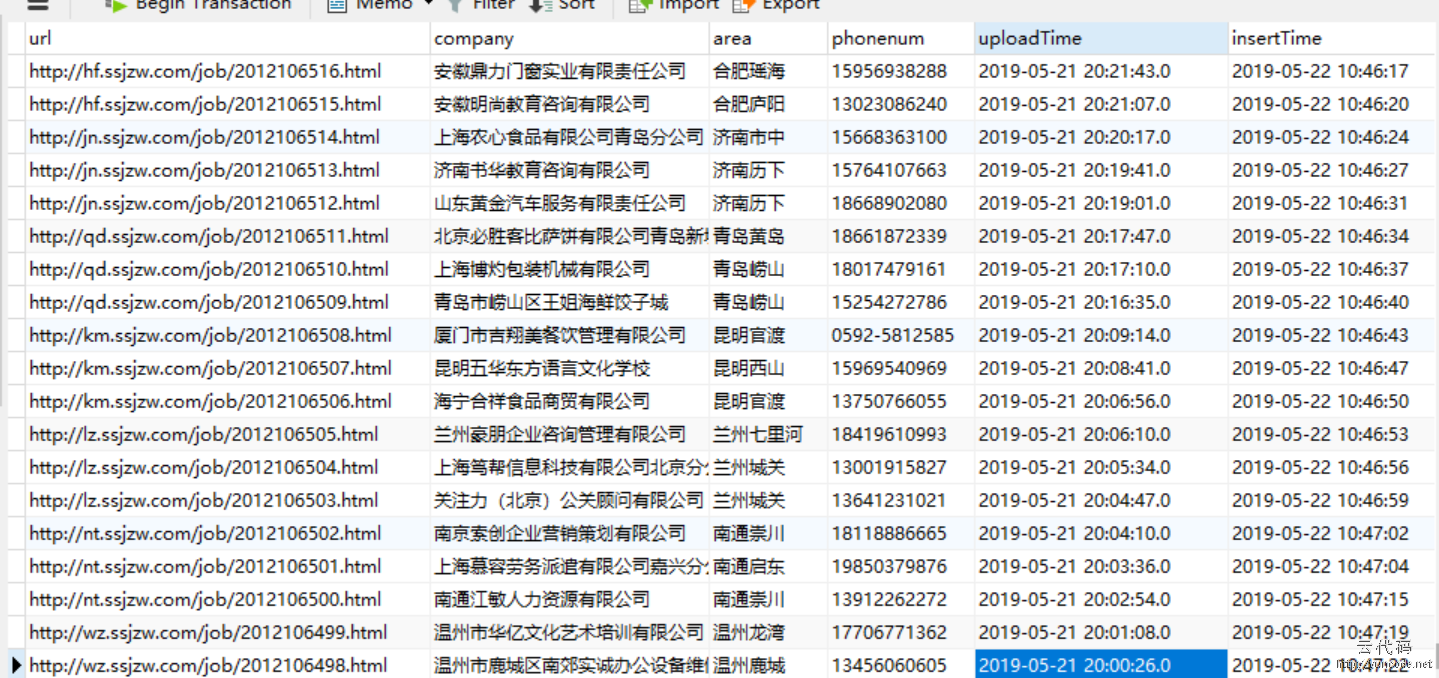
[代码运行效果截图]
[源代码打包下载]








 孩子要交作业了
孩子要交作业了
初级程序员
by: hong 发表于:2019-06-14 12:46:00 顶(14) | 踩(9) 回复
謝謝
回复评论