[python]代码库
#定义合并单元格的函数
def Merge_cells(table,target_list,start_row,col):
'''
table: 是需要操作的表格
target_list: 是目标列表,即含有重复数据的列表
start_row: 是开始行,即表格中开始比对数据的行(需要将标题除开)
col: 是需要处理数据的列
'''
start = 0 #开始行计数
end = 0 #结束行计数
reference = target_list[0] #设定基准,以列表中的第一个字符串开始
for i in range(len(target_list)): #遍历列表
if target_list[i] != reference: #开始比对,如果内容不同执行如下
reference = target_list[i] #基准变成列表中下一个字符串
end = i - 1
table.cell(start+start_row,col).merge(table.cell(end+start_row,col))
start = end + 1
if i == len(target_list) - 1: #遍历到最后一行,按如下操作
end = i
table.cell(start+start_row,col).merge(table.cell(end+start_row,col))
from docx import Document
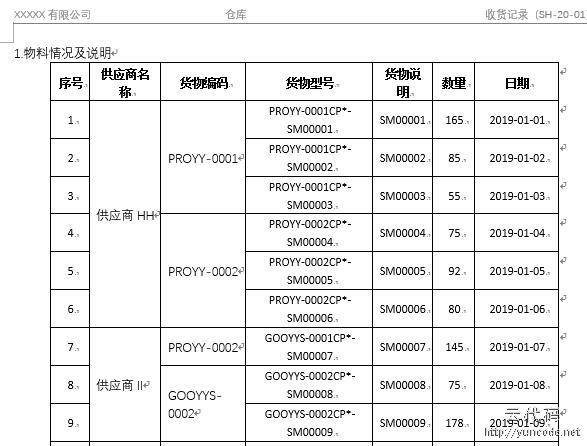
doc = Document("收货记录.docx")
#读取word文档中的第一个表格的第二和第三列除标题和尾部总数行的数据
table = doc.tables[0] #已确定是第一个表格,其索引是0
supplier = [] #存储供应商名称
pn = [] #存储物料编码
max_row = len(table.rows) #获取第最大一行
#读取第二行到29行,第2,3列中的数据
for i in range(1,max_row-1):
supplier_name = table.rows[i].cells[1].text #cells[1]指表格第二列
supplier.append(supplier_name)
for i in range(1,max_row-1):
material_pn = table.rows[i].cells[2].text #cells[2]指表格第三列
pn.append(material_pn)
Merge_cells(table,supplier,1,1) #开始合并行为2,索引为1;供应商名称是在2列,索引为1
Merge_cells(table,pn,1,2) #开始合并行为2,索引为1;物料编码是在3列,索引为2
#重新往第2和第3列写入数据,以覆盖之前重复的数据
for row in range(1,len(supplier)+1):
table.cell(row,1).text = supplier[row-2]
table.cell(row,2).text = pn[row-2]
doc.save("收货记录-合并单元格.docx")
[代码运行效果截图]