[python]代码库
#!/usr/bin/env python
# encoding: utf-8
import cv2
import random
import numpy as np
class digitalPicture:
'''
This is a main Class, the file contains all documents.
One document contains paragraphs that have several sentences
It loads the original file and converts the original file to new content
Then the new content will be saved by this class
'''
def __init__(self):
self.picture = 'assets/picture.jpeg'
def hello(self):
'''
This is a welcome speech
:return: self
'''
return self
def run(self):
'''
The program entry
'''
img = cv2.imread(self.picture)
str_img = self.img_to_string(img)
cv2.imwrite('result.jpg', str_img)
print('处理完成!!!!')
def img_to_string(self, frame, K=6):
"""
利用 聚类 将像素信息聚为3或5类,颜色最深的一类用数字密集地表示,阴影的一类用“-”横杠表示,明亮部分空白表示。
---------------------------------
frame:需要传入的图片信息。可以是opencv的cv2.imread()得到的数组,也可以是Pillow的Image.read()。
K:聚类数量,推荐的K为3或5。根据经验,3或5时可以较为优秀地处理很多图像了。若默认的K=5无法很好地表现原图,请修改为3进行尝试。若依然无法很好地表现原图,请换图尝试。 ( -_-|| )
---------------------------------
聚类数目理论可以取大于等于3的任意整数。但水平有限,无法自动判断当生成的字符画可以更好地表现原图细节时,“黑暗”、“阴影”、”明亮“之间边界在哪。所以说由于无法有效利用更大的聚类数量,那么便先简单地限制聚类数目为3和5。
"""
if type(frame) != np.ndarray:
frame = np.array(frame)
height, width, *_ = frame.shape # 有时返回两个值,有时三个值
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frame_array = np.float32(frame_gray.reshape(-1))
# 设置相关参数。
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
flags = cv2.KMEANS_RANDOM_CENTERS
# 得到labels(类别)、centroids(矩心)。
# 如第一行6个像素labels=[0,2,2,1,2,0],则意味着6个像素分别对应着 第1个矩心、第3个矩心、第3、2、3、1个矩心。
compactness, labels, centroids = cv2.kmeans(frame_array, K, None, criteria, 10, flags)
centroids = np.uint8(centroids)
# labels的数个矩心以随机顺序排列,所以需要简单处理矩心.
centroids = centroids.flatten()
centroids_sorted = sorted(centroids)
# 获得不同centroids的明暗程度,0最暗
centroids_index = np.array([centroids_sorted.index(value) for value in centroids])
bright = [abs((3 * i - 2 * K) / (3 * K)) for i in range(1, 1 + K)]
bright_bound = bright.index(np.min(bright))
shadow = [abs((3 * i - K) / (3 * K)) for i in range(1, 1 + K)]
shadow_bound = shadow.index(np.min(shadow))
labels = labels.flatten()
# 将labels转变为实际的明暗程度列表,0最暗。
labels = centroids_index[labels]
# 列表解析,每2*2个像素挑选出一个,组成(height*width*灰)数组。
labels_picked = [labels[rows * width:(rows + 1) * width:2] for rows in range(0, height, 2)]
canvas = np.zeros((3 * height, 3 * width, 3), np.uint8)
canvas.fill(255) # 创建长宽为原图三倍的白色画布。
# 因为 字体大小为0.45时,每个数字占6*6个像素,而白底画布为原图三倍
# 所以 需要原图中每2*2个像素中挑取一个,在白底画布中由6*6像素大小的数字表示这个像素信息。
y = 8
for rows in labels_picked:
x = 0
for cols in rows:
if cols <= shadow_bound:
cv2.putText(canvas, str(random.randint(2, 9)),
(x, y), cv2.FONT_HERSHEY_PLAIN, 0.45, 1)
elif cols <= bright_bound:
cv2.putText(canvas, "-", (x, y),
cv2.FONT_HERSHEY_PLAIN, 0.4, 0, 1)
x += 6
y += 6
return canvas
if __name__ == '__main__':
digitalPicture().hello().run()
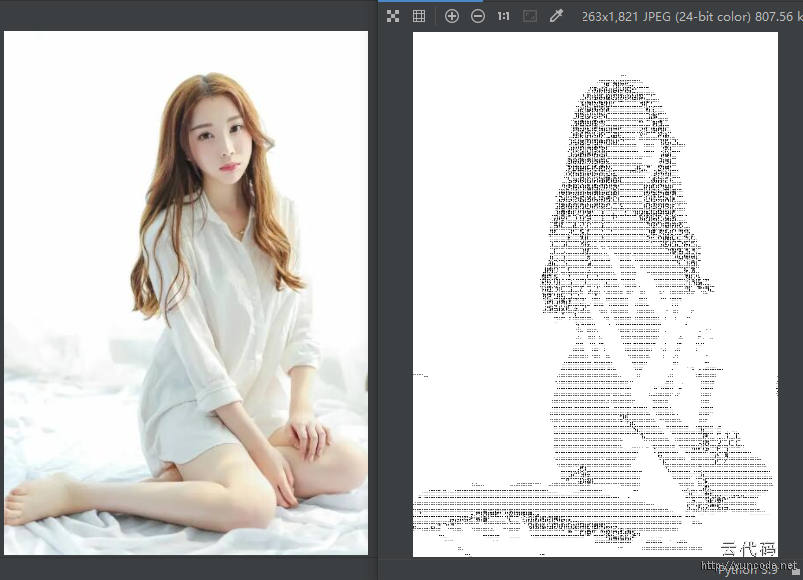
[代码运行效果截图]
[源代码打包下载]